How to Tackle Logistic Regression Assignments Using R

Claim Your Offer
Unlock a fantastic deal at www.statisticsassignmenthelp.com with our latest offer. Get an incredible 10% off on all statistics assignment, ensuring quality help at a cheap price. Our expert team is ready to assist you, making your academic journey smoother and more affordable. Don't miss out on this opportunity to enhance your skills and save on your studies. Take advantage of our offer now and secure top-notch help for your statistics assignments.
We Accept









- Understanding Logistic Regression
- What Is Logistic Regression?
- When Should You Use Logistic Regression?
- Preparing Data for Logistic Regression in R
- Loading and Exploring the Dataset
- Handling Categorical Variables
- Building the Logistic Regression Model
- Fitting the Model Using glm()
- Interpreting Model Coefficients
- Evaluating and Validating the Model
- Common Challenges and Solutions
- Dealing with Overfitting
- Handling Multicollinearity
- Conclusion
Logistic regression is a fundamental statistical method used for predicting binary outcomes, making it a crucial tool in fields like medicine, marketing, and social sciences. Whether you're working on a class assignment or analyzing real-world data, understanding how to implement logistic regression in R is essential. This guide provides a structured approach to logistic regression, covering data preparation, model building, evaluation, and troubleshooting—ensuring you can confidently complete your logistic regression assignments.
Understanding Logistic Regression
Before diving into implementation, it's important to grasp what logistic regression is and when it should be used. Unlike linear regression which predicts continuous values, logistic regression specializes in binary classification problems. This section explains the mathematical foundation of logistic regression and its ideal use cases, helping you determine if it's the right approach for your data analysis needs.

What Is Logistic Regression?
Logistic regression is a statistical technique used to model the probability of a binary outcome (e.g., yes/no, pass/fail, disease/no disease). Unlike linear regression, which predicts continuous values, logistic regression estimates probabilities using the logistic function (also called the sigmoid function), which outputs values between 0 and 1.
The logistic regression equation is:
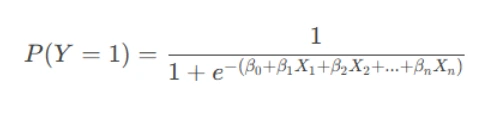
- P(Y=1) is the probability of the event occurring.
- β0 is the intercept.
- β1, β2, ..., βn are the coefficients for predictors X1, X2, ..., Xn.
- e is the base of the natural logarithm.
When Should You Use Logistic Regression?
Logistic regression is suitable when:
- The dependent variable is binary (e.g., success/failure, 0/1).
- You need to understand the relationship between predictors and a categorical outcome.
- The goal is classification or probability estimation (e.g., predicting loan defaults, customer churn, or medical diagnoses).
It is not appropriate for:
- Continuous outcomes (use linear regression instead).
- Multi-class classification (unless extended to multinomial logistic regression).
Preparing Data for Logistic Regression in R
Proper data preparation is critical for building an accurate logistic regression model. This section covers essential steps for getting your dataset ready, including importing data, handling missing values, and converting categorical variables. These preprocessing steps ensure your data is in the right format before model building begins.
Loading and Exploring the Dataset
Before building a logistic regression model, you must:
- Import the Data
- Inspect the Data
- Handle Missing Data
data <- read.csv("your_dataset.csv")
If your data is in Excel, use:
library(readxl)
data <- read_excel("your_dataset.xlsx")
Check the structure:
str(data)
View summary statistics:
summary(data)
Look for missing values:
sum(is.na(data))
Remove rows with missing values (if few):
data <- na.omit(data)
Impute missing values (if necessary):
data$column[is.na(data$column)] <- mean(data$column, na.rm = TRUE)
Handling Categorical Variables
Since logistic regression requires numerical inputs, categorical predictors (e.g., gender, education level) must be converted into factors or dummy variables.
- Convert to Factors
- Check Levels
- Dummy Variable Encoding (if needed)
data$gender <- as.factor(data$gender)
levels(data$gender)
R’s glm() function automatically handles factors, but if manual encoding is required:
library(fastDummies)
data <- dummy_cols(data, select_columns = "gender", remove_first_dummy = TRUE)
Building the Logistic Regression Model
With prepared data, the next step is constructing the logistic regression model. This section walks through fitting the model in R using the glm() function and interpreting the results. Understanding model coefficients and their significance is key to drawing meaningful conclusions from your analysis.
Fitting the Model Using glm()
In R, logistic regression is performed using the Generalized Linear Model (glm()) function with family = binomial:
model <- glm(outcome ~ predictor1 + predictor2, data = data, family = binomial)
- outcome: Binary dependent variable (0/1).
- predictor1, predictor2: Independent variables.
- family = binomial: Specifies logistic regression.
Interpreting Model Coefficients
After fitting the model, examine the summary:
summary(model)
Key outputs:
- Coefficients (Estimate): Represent log-odds.
- P-values (Pr(>|z|)): Indicate statistical significance (p < 0.05 suggests significance).
To convert log-odds to odds ratios for easier interpretation:
exp(coef(model))
Example Interpretation:
If the coefficient for predictor1 is 0.5, the odds ratio is e0.5 ≈ 1.65, meaning a one-unit increase in predictor1 increases the odds of the outcome by 65%.
Evaluating and Validating the Model
After building your model, it's crucial to assess its performance and validity. This section explores various metrics and techniques for evaluating logistic regression models, including goodness-of-fit tests and predictive accuracy checks. These evaluations help ensure your model is reliable and generalizable to new data.
Assessing Model Fit
Several metrics help evaluate logistic regression models:
- Akaike Information Criterion (AIC)
- Lower AIC indicates a better-fitting model.
- Compare models using:
- Likelihood Ratio Test
- Pseudo R-Squared (McFadden’s R²)
AIC(model1, model2)
Tests if adding predictors improves the model:
anova(null_model, full_model, test = "Chisq")
Measures explained variance (values closer to 1 indicate better fit):
library(pscl)
pR2(model)
Predicting and Validating Accuracy
To test the model’s predictive power:
- Split Data into Training & Test Sets
- Predict Probabilities on Test Data
- Evaluate Classification Accuracy
set.seed(123)
train_index <- sample(1:nrow(data), 0.7 * nrow(data))
train_data <- data[train_index, ]
test_data <- data[-train_index, ]
predictions <- predict(model, newdata = test_data, type = "response")
Convert probabilities to binary predictions (using 0.5 threshold):
predicted_class <- ifelse(predictions > 0.5, 1, 0)
Generate a confusion matrix:
table(Predicted = predicted_class, Actual = test_data$outcome)
Calculate accuracy:
mean(predicted_class == test_data$outcome)
Common Challenges and Solutions
Even with a well-built model, challenges like overfitting and multicollinearity can arise. This section addresses these common issues and provides practical solutions to enhance your model's performance. Learning to identify and resolve these problems will improve the robustness of your logistic regression analyses.
Dealing with Overfitting
Overfitting occurs when the model performs well on training data but poorly on unseen data.
Solutions:
- Feature Selection: Use stepwise regression to remove non-significant predictors:
- Regularization (LASSO/Ridge):
step_model <- step(model, direction = "both")
library(glmnet)
cv_model <- cv.glmnet(x, y, alpha = 1, family = "binomial") # LASSO
Handling Multicollinearity
High correlation between predictors can distort coefficients.
Detection:
library(car)
vif(model) # VIF > 5 indicates multicollinearity
Solutions:
- Remove highly correlated predictors.
- Use Principal Component Analysis (PCA) for dimensionality reduction.
Conclusion
Logistic regression is a powerful tool for binary classification tasks in statistics. By following these steps—data preparation, model fitting, evaluation, and troubleshooting—you can confidently do your R assignment on logistic regression. Practice with real datasets and refine your approach to build accurate, interpretable models. These skills will not only help you complete your coursework but also prepare you for real-world data analysis challenges.
By mastering these techniques, you'll not only solve your Statistics assignment effectively but also develop skills applicable to real-world data analysis. If you encounter difficulties, revisiting foundational concepts or consulting additional resources can further strengthen your understanding.